语音识别技术的应用领域及系统分类

语音识别在智能家居中的重要性
2021年12月13日
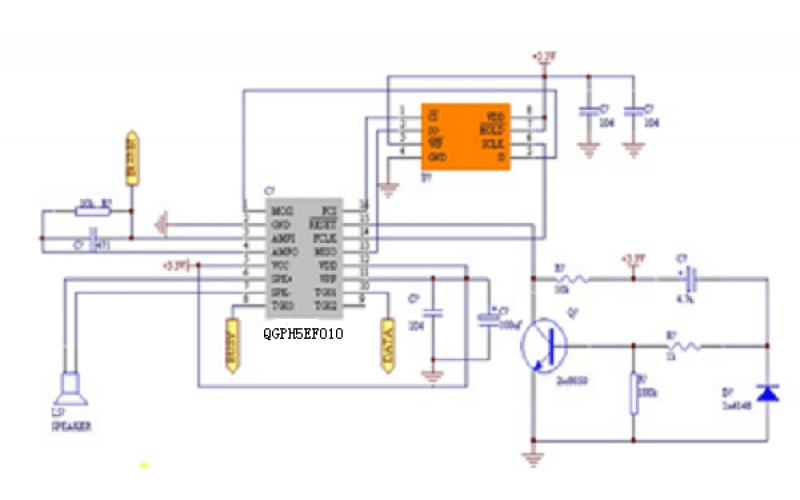
浅析国内外语音识别技术发展现状(语音芯片)
2021年12月13日
语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入, 语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
语音识别技术可以说是当下科技圈的又一个热点,现如今语音识别系统在便携设备上得到广泛的运用,从智能手机到智能手表智能手环上都携带得有语音识别系统。自动语音识别就是使设备可以听懂用户的话,识别又分为篇章级识别和命令词识别,目前在嵌入式领域发展比较成熟的只有命令词的识别。语音识别就像给设备安装了耳朵,让设备可以听懂我们的命令,并且执行相应的命令,解决了人们在操作各种终端设备时只能使用手动按键方式的问题。
语音识别系统可以根据对输入语音的限制加以分类,如果从说话者与识别系统的相关性考虑,可以将识别系统分成三类:特定人语音识别系统,仅考虑对于专人的话音进行识别;非特定人语音系统:识别的语音与人无关,通常要用大量不同人的语音数据库对识别系统进行学习;多人的识别系统:通常能识别一组人的语音,或者成为特定组语音识别系统,该系统仅要求对要识别的那组人的语音进行训练。
如果从从说话的方式考虑,也可以将识别系统分为三类:孤立词语音识别系统;孤立词识别系统要求输入每个词后要停顿;连接词语音识别系统;连接词输入系统要求对每个词都清楚发音,一些连音现象开始出现;连续语音识别系统;连续语音输入是自然流利的连续语音输入,大量连音和变音会出现。

如果是从识别系统的词汇量大小考虑,也可以将识别系统分为三类:小词汇量语音识别系统,通常包括几十个词的语音识别系统;中等词汇量的语音识别系统。通常包括几百个词到上千个词的识别系统;大词汇量语音识别系统。通常包括几千到几万个词的语音识别系统。随着计算机与数字信号处理器运算能力以及识别系统精度的提高,识别系统根据词汇量大小进行分类也不断进行变化。目前是中等词汇量的识别系统到将来可能就是小词汇量的语音识别系统。这些不同的限制也确定了语音识别系统的困难度。
目前具有代表性的语音识别方法主要有:动态时间规整(DTW),隐马尔可夫法(HMM),矢量量化(VQ),人工神经网络(ANN)等方法。
动态时间规(DTW)由于语音信号是一种具有相当大随机性的信号,即使相同说话者对相同的词,每一次发音的结果都是不同的,不可能具有完全相同的时间长度。因此在与已存储模型相匹配时,未知单词的时间轴要不均匀地扭曲或弯折,以使其特征与模板特征对正。用时间规整手段对正是一种非常有力的措施,对提高系统的识别精度非常有效。
隐马尔可夫模型(HMM)是Markov链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程—-具有一定状态数的隐马尔可夫链和显示随机函数集。HMM方法现已成为语音识别的主流技术,目前大多数大词汇量、连续语音的非特定人语音识别系统都是基于HMM模型的。
矢量量化(VectorQuantization)是一种重要的信号压缩方法。VQ在语音信号处理中占十分重要的地位;广泛应用于语音编码、语音识别和语音合成等领域。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。将矢量空间分成若干个小区域,每个小区域有一个代表矢量,当输入矢量落入某个区域时,量化成该代表矢量。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量,实现最大可能的平均信噪比。
人工神经网络的方法(ANN)是80年代末期提出的一种新的语音识别方法。本质上是一个自适应非线性动力学系统,模拟了人类神经活动的原理,具有自适应性、并行性、鲁棒性、容错性和学习特性,其强的分类能力和输入-输出映射能力在语音识别中都很有吸引力。人工神经网络的独特知识表示结构和信息处理原则使其成为智能信息处理的主要技术之一,吸引了越来越多科技工作者的研究兴趣。